

也谈深度学习中的一阶优化算法
- 发表时间:2024-05-13
- 来源:网络
- 人气:
深度学习有一个melody:model, evaluation, loss, optimization, and dataset. 它们相互交织,每个部分都对最终的performance有一定影响。所以其实脱离了melody单独谈optimization是耍流氓行为。实际应用中肯定是要结合具体的task(dataset)和model architecture等来选择优化算法的。但优化算法要不要单独研究呢?我觉得还是有一定必要的。一方面是速度上,好的优化算法是真的快(比如FISTA,或是各种分布式的算法);另一方面,人们也的确想来理解不同的算法区别到底在哪里,以及怎么来选择。
本文是基于一些实践以及相关的论文而谈的。很多见解也被放在了我们的一篇论文里:
Nostalgic Adam: Weighting more of the past gradients when designing adaptive learning rate 。 欢迎大家阅读、批评、引用!
深度学习中的优化算法常用的主要有两种,基于梯度的和不基于梯度的。我个人觉得不基于梯度的算法现在还不是很成熟。基于梯度的肯定都是一阶梯度,因为二阶梯度的话是存不下那么大的Hessian矩阵的。一阶梯度算法可以被概括为如下表达式: 其中
可以看作对gradient的一个估计。最为简单的形式就是SGD:
以及目前可能是最常用的momentum形式:
这类算法其实已经讨论的非常多了,乃至对应的dynamics都已经分析清楚了,见下面这篇Weijie Su的经典论文:
Nesterov, momentum,加上SGD,这可以算作一类算法。
另一类算法是所谓的adaptive算法, 最早是2012年AdaGrad被提出,后来Adam的“又快又好”让这类算法大行其道。不过近年来又因其在一些task上的generalization performance不如SGD类算法而被诟病。在上面的框架下,Adam的算法可以被写作
同时,因为Adam类算法构造的有一些“违反直觉”,很多人都不是特别理解这个算法的本质(实际上是不理解 的含义)。这类算法的理论研究比较少。我之后主要谈的是这类算法。
- Non-convergence Issue. 这方面最重要的工作就是18年ICLR的best paper: On the Convergence of Adam and Beyond. 他们对Adam的证明进行了分析,发现了两个bugs,其中比较致命的bug是
的估计,Adam的
,他们还找出了一个例子让Adam不收敛。解决方案是用
来在
的更新式中代替
这篇文章是很有启发性的,之后有好多篇文章是基于这篇文章又给出了一些改进的Adam variants. 比如有一篇叫AdaShift,作者从AMSGrad一文中的那个反例出发进行分析,获得了一个新算法。但实际上这个反例是非常artificial的,最不自然的就是repetitive gradients,即梯度是周期性反复出现的,这在实际情况中是不可能出现的。另一个比较有意思的工作是AdaBound,我之前已经有过一些讨论了:
如何评价优化算法 AdaBound?这些文章有一个共同点是都觉得不能像Adam一样完全地“信任”当下的gradient。我们的论文要更进一步:我们要求在设计 时,要对过去的gradient给予更大的权重。算法的motivation也是从证明里来的,这个我放到后面说。
2. Generalization
之前在各种优化算法爆炸性增长的时候(14年左右)大家还没来得及关心泛化,都关心算法快慢,调参难易等等。但现在越来越多的人注意到泛化才是最重要的。而17年的时候,终于有人写了篇论文来怼Adam类算法的泛化问题,标题也起的很悲观:
The Marginal Value of Adaptive Gradient Methods in Machine Learning粗暴地总结就是论文对一些常见的task做了实验,得出了adaptive算法的泛化很烂的结论。但事实是否的确如此呢?我觉得并不是。从实践看,像Google最新的BERT就是用AdamW优化的;从理论看,我觉得有一篇文章很能说明问题:
Dissecting Adam: The Sign, Magnitude and Variance of Stochastic Gradients这篇文章发表在2018年的ICML。文章有两个亮点很吸引我,第一就是讨论了SGD类算法和Adam类算法分别在什么时候work;另一个是基于second-moment的假设,对 的作用进行了一个分析。细节可能需要大家自己去读文章,我这里就谈第一个点。
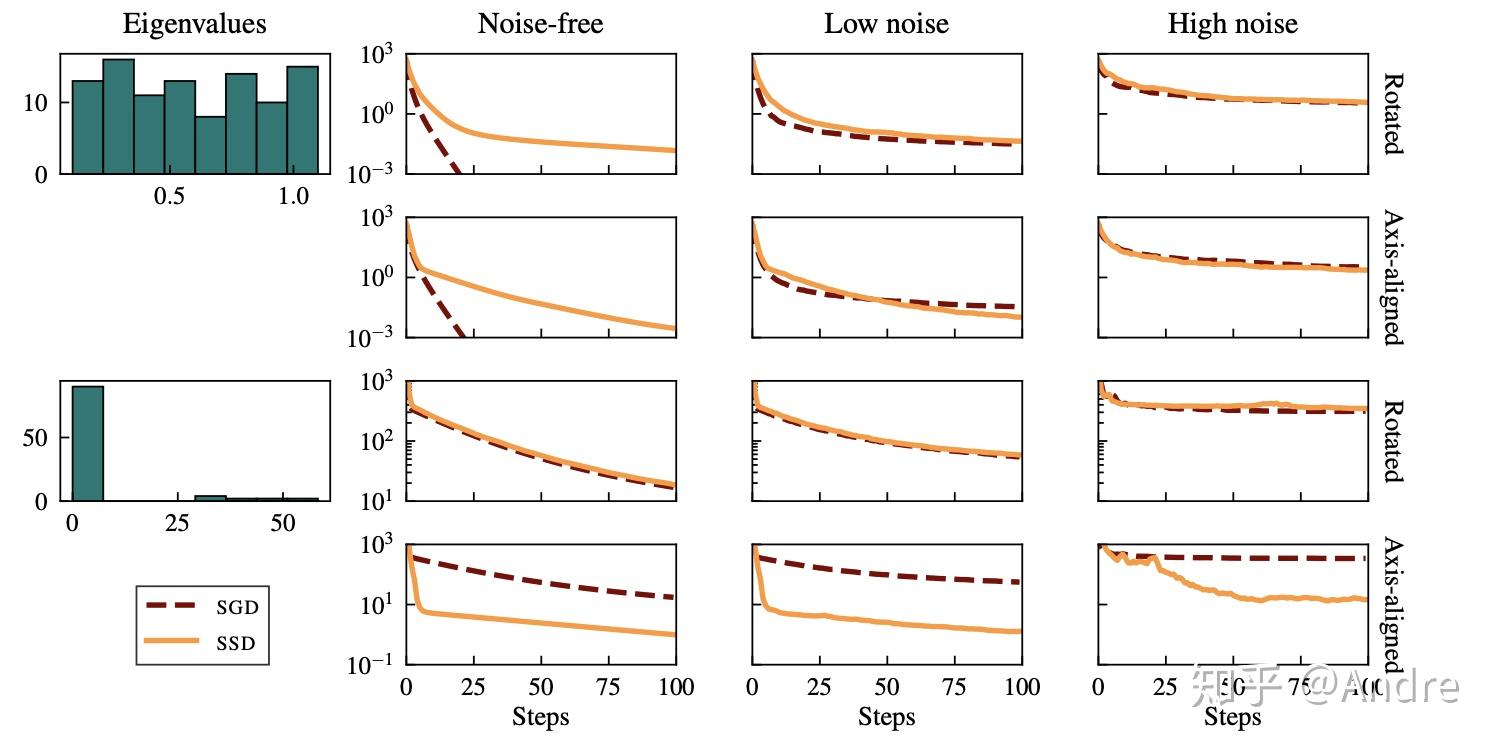
上图中比较了SGD和SSD(即Adam类)算法在一个二次问题中,不同noise, 不同条件数以及二次矩阵是否为对角矩阵(rotated or axis-aligned) 情况下的performance。文章中还对这个model problem做了比较充分的理论分析。一些简单的结论有:
a. 梯度的noise大时,Adam类比SGD类好;
b. loss看作二次函数时,二次矩阵的数值越大,SGD越好(文中的量 ).
c. 问题的条件数越大,SGD越不好。
这些结论,配合实验(论文里还做了很多实验)都说明了其实SGD类算法和Adam类算法的performance是相当problem-dependent的。这也可能可以解释为什么某些问题上SGD(momentum)的确比Adam好一大截。
在实际做选择的时候,不可能真的去算条件数或是noise,更可行的是把两类算法都试试,一类不行就试另一类。
3. 的作用
刚才已经说了,Dissecting Adam里面对 的作用有过讨论,但是是基于
是
的approximation这一假设的。这个假设对不对呢?很难说。有一篇叫PAdam的工作,把Adam中的
替换成了
,发现不仅理论上依然收敛,实验结果也非常说的过去。然后在我们论文的supplement里面,我们证明了一个"p-norm"版本的NosAdam的收敛性,即
. 这些可能都说明了把
解释成second-moment estimate是不太科学的。
不过 是怎么其作用的还真不好说。我个人目前的理解与AdaGrad中的一个比较直觉的解释类似,直接搬运过来吧:
“the adaptation allows us to find needles in haystacks in the form of very predictive but rarely seen features.”
大意就是 实际上是在根据不同feature的出现频率在balance它们的更新速度:经常出现的feature
就会大一些,那么一倒数就会让对应的
更新慢一点。这一理解可以帮助我们理解一个叫SWATS的工作(Improving Generalization Performance by Switching from Adam to SGD)。这个工作的大意是先用Adam,找到一个合适的
之后就固定下来,转成SGD。这似乎告诉我们在每个coordinate上存在着一个optimal rescaling factor
,我们的目的就是把它们找到,来平衡不同coordinate的更新速度。
这个理解是相当直观的,但“很有可能”有点道理。像目前算是站得住脚的AMSGrad, AdaBound和NosAdam(勉强算吧),都符合这个特点,即rescaling factor在逐渐的固定下来。这是一个很有意思的问题,也许会再出几篇不错的paper。
说了这么多别人家的算法,我也要谈一谈我们的算法究竟是什么,可以为我们提供什么insight。我们的第一个想法是让 Adam中的 变起来,与
相关,即
. 再把它表示成两项之商
,由此任意一个递增正数列
都可以定义出一系列的
,如果再定义
,则
是任意一个正数列。那么之前所说的收敛证明中要求的
要正定的条件意味着什么呢?
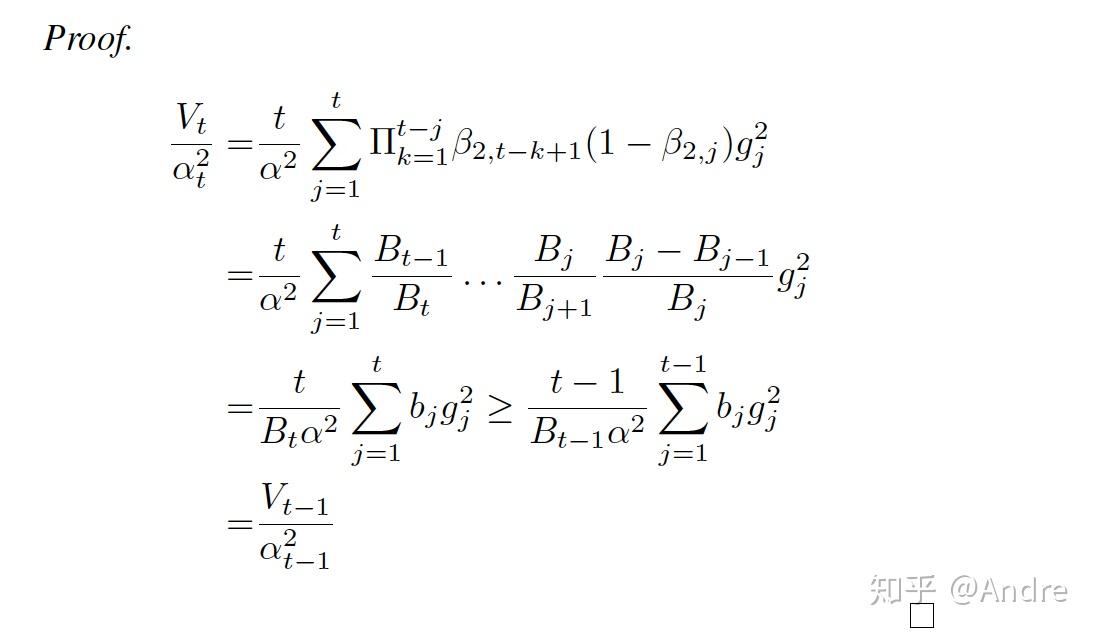
而如果 是个单调序列(在Adam中它单调增),我们又可以证明
is non-increasing if and only if
is non-increasing. 这是与Adam挺重要的一个区别。注意到
, 我们可以看到
序列的不增就意味着,在
的计算中,我们要对过去的
给予更多的权重。
算法的核心就这么简单,写成伪代码就是:

除了 序列不增,我们还需要另一个收敛性条件,但这两个收敛性条件都是很容易check的,而且可以在设计
的时候都完成,完全是data-independent。下面是收敛性的定理。

其实我们还证明过一个非凸情况下的收敛性,不过完全是follow相关文章的证明,新意不大(见On the Convergence of A Class of Adam-Type Algorithms)。
特别的呢,我们找出了满足上述收敛条件的一组参数,它们是hyperharmonic series,因此这个特殊情形也叫NosAdam-HH,即 。之后做的实验都是用的这个具体的算法。NosAdam其实只是一个框架。
我觉得一个有意思的发现是不够的,我们肯定是要努力去解释解释(虽然可能是强行解释)。我们先来把几个算法的 写出来。
,
AMSGrad不太好直接写,但可以写作 ,这里n是depends on data的,即取的是
中最大的
. AdaShift也可以用上式表示,不过n是个常数。
这样一来,我们就可以作图了:
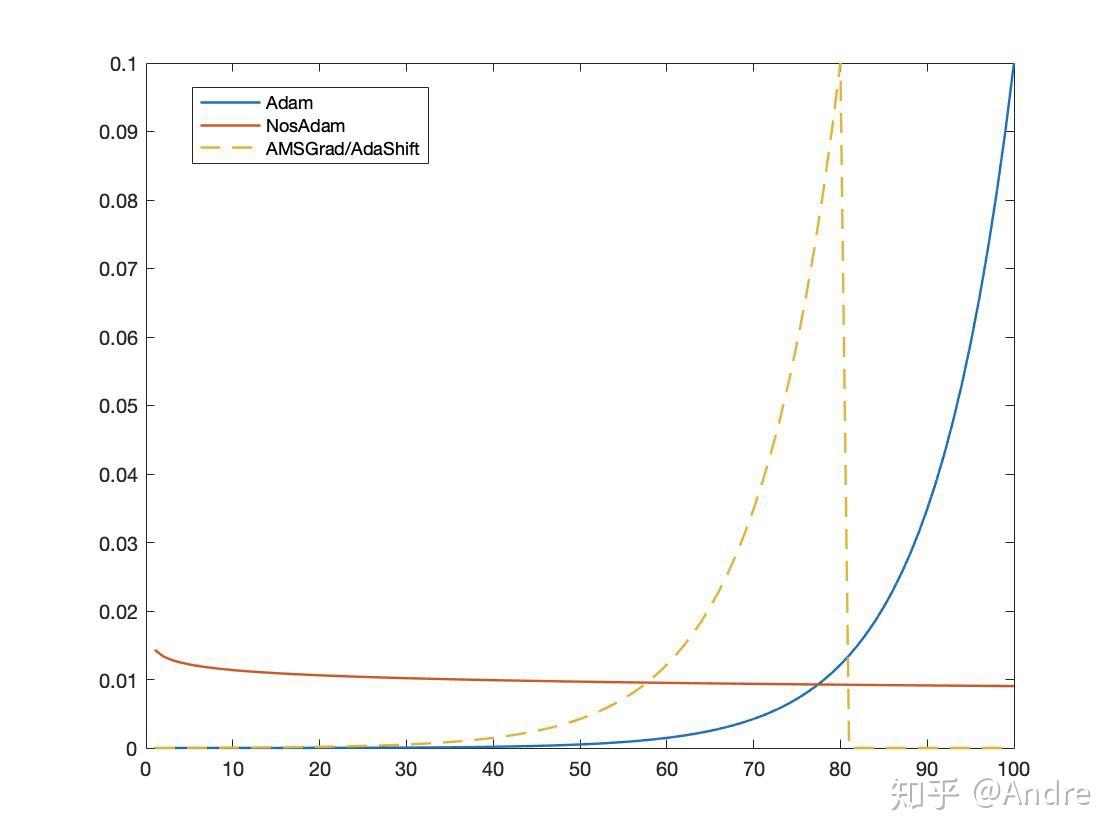
从这个比较首先可以看出Adam的一个缺陷,就是 过分以来最近的gradient,这样以来万一gradient一直很小,
就会特别小,那么步长就会很大,就不稳定了(乃至发散)。
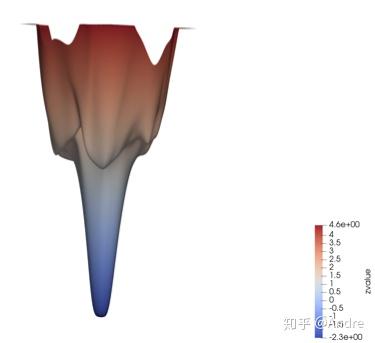
AMSGrad一文中的例子太artificial了,我这里给一个新的例子(参考了老板的老板的文章LSGD),同时提供一种从landscape来思考算法的视角,个人觉得还是比较有意思而且promising的:
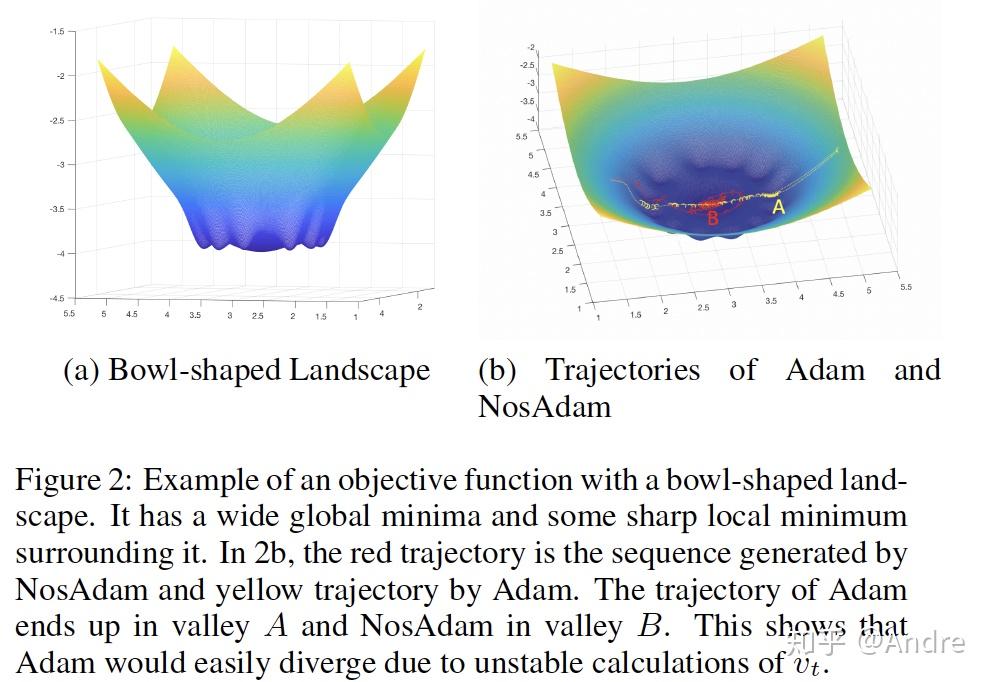
我这里就只放图不多解释了,简单说就是在这个底部比较平坦的情况下,Adam会不收敛,但是NosAdam完全OK。
那AMSGrad又有什么问题呢?它的确客服了发散,但它最大的问题是 容易被极端值影响,而且一旦变大就没法变小了,下面是一个例子:
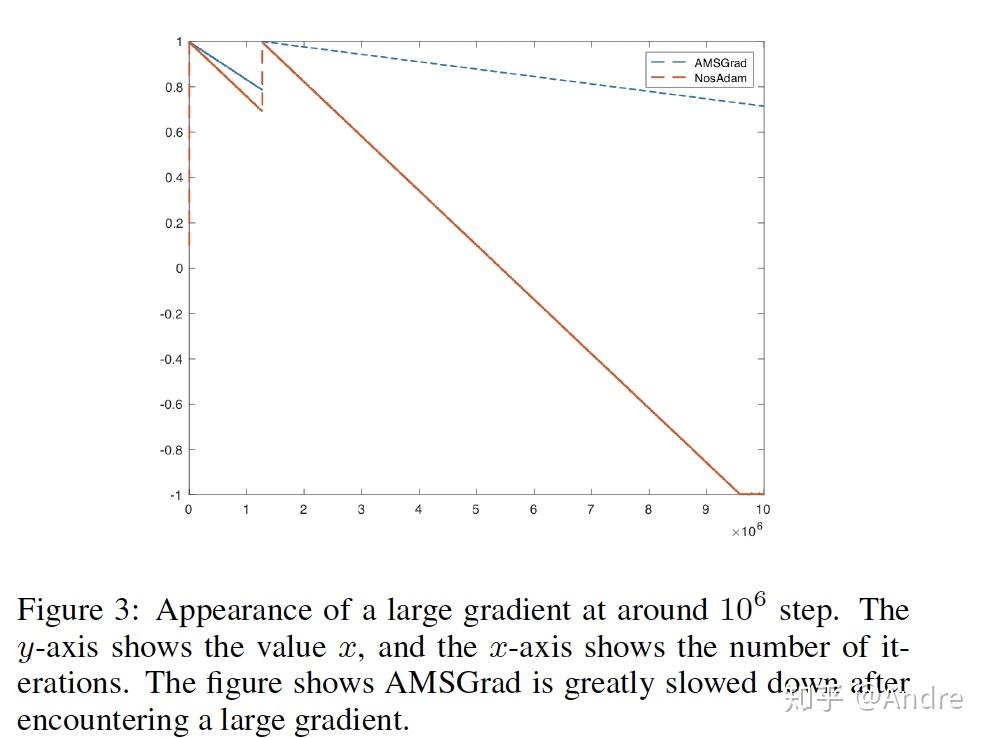
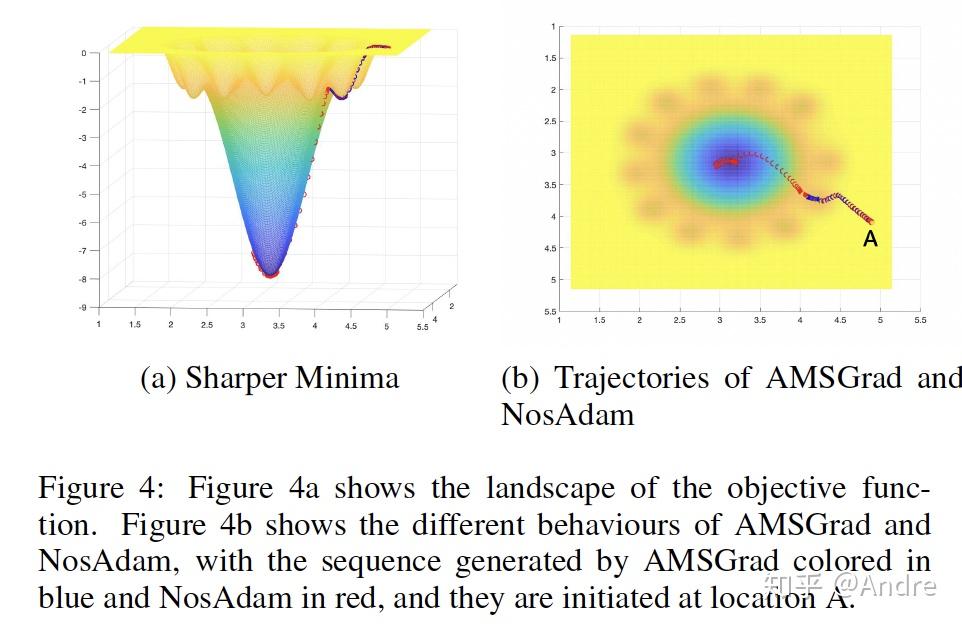
一个更真实的例子是在sharp local minimum处,由于梯度比较大,可能会造成AMSGrad中的 过大,而且无法变小,因此被trap住:
但每种方法都有其优劣。NosAdam的坏处是对初始条件依赖比较大——它需要有一个“美好的童年”,否则是没必要nostalgic的。我也构造了一个NosAdam不如Adam的例子,即initiate在local minima附近:
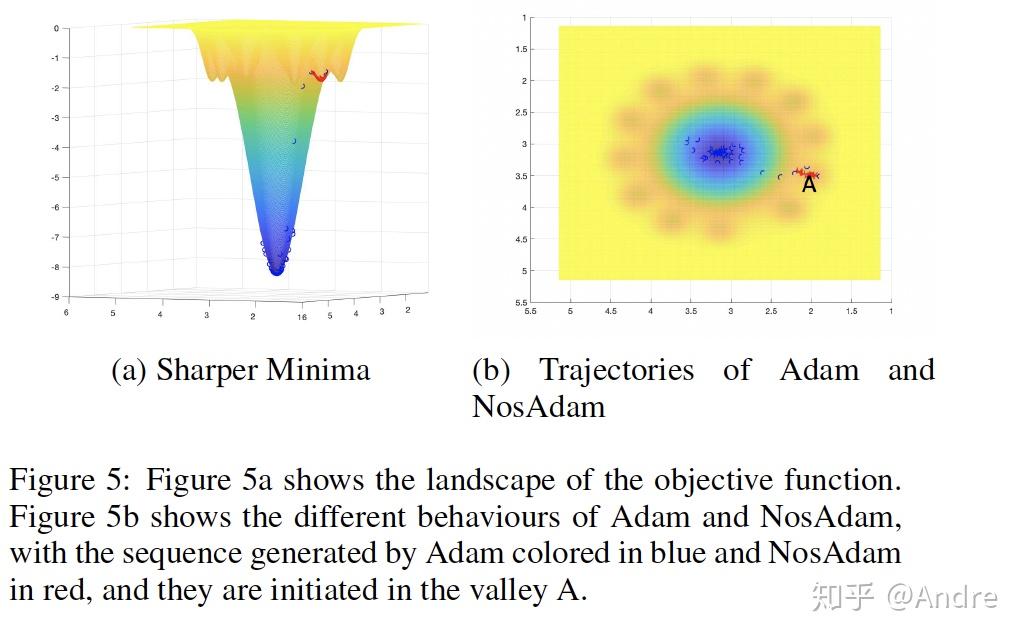
这一系列例子都很清楚地展现出了Adam类算法在不同landscape下的表现,尤其是对initial condition的sensitivity。至于实际的initial condition究竟如何呢?有一些相关的工作发现,有skip connections的architecture(即ResNet类网络)配合上Kaiming's initialization能有相当好的loss landscape,放两张图:
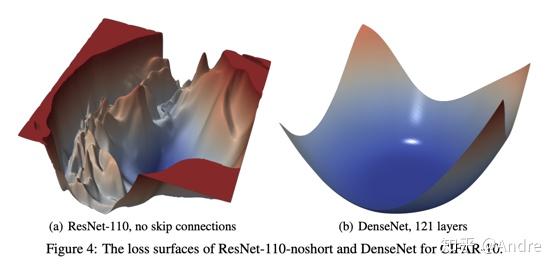
个人觉得这个角度(loss landscape)对优化算法的思考是有益的,它可以帮我们(部分地)理解很多优化算法为什么work,为什么不work,以及什么时候work或不work。比如从上图的ResNet56 on CIFAR10的 loss landscape可以看出,NosAdam应该是会work的(跟我们的例子中的landscape基本一样)。
首先我得承认我是手残,实验做的很渣,没有在ImageNet很好地跑过(试过,太耗时间就没再试了……),对于下面的实验,代码可见https://github.com/andrehuang/NostalgicAdam-NosAdam。
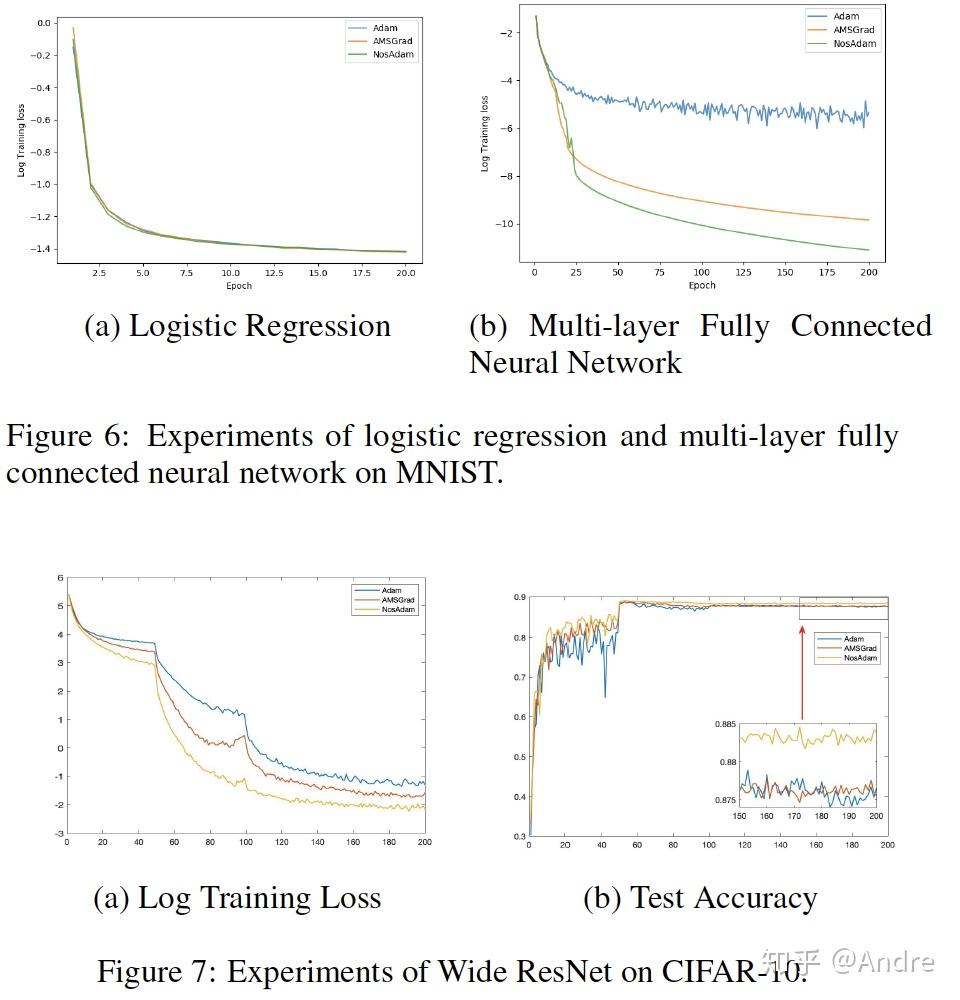
虽然夹带着私货,写本文的初衷其实还是想把深度学习中的一阶优化算法有一个比较清楚的讨论,这也是我过去这一年来断断续续折腾和思考的结果。我觉得上面的讨论还是能够让我们对一阶优化算法有一个比较清晰的认识的。
至于take-home message,
to practioner:如果Adam类算法不行,就上momentum;如果momentum不行,就上Adam类(AdamW, AMSGrad...),特别地,别忘了NosAdam。
to theory-lover: 文章里有好多坑可以做呀! 的作用?怎样从landscape的角度进一步把问题分析清楚(more sensitivity analysis?) ?以及那个关于
的猜想是否是对的——数据分布均匀与否是否会影响两类算法的表现?(这个肯定是可以上手做的)
希望对大家能有一些帮助吧!
- 2025-06-01张雪峰谈广东工业大学:和211的差距对比、热门专业推荐
- 2025-06-01广东外语外贸大学国际商务英语学院国际本科出国留学培训项目招生简章(2022年)
- 2025-06-01雅思报班学
- 2025-06-01张雪峰调侃二本女生,伤害性不大,侮辱性却极强,过来人却直呼现实!
- 2025-06-01海外留学 就读生命科学专业的四大就业方向
- 2025-06-01药学专业的学生,出国留学可以读什么?
- 2025-06-01航空工程学院推荐2025年优秀应届本科毕业生免试攻读硕士学位研究生工作通知
- 2025-06-01计算机科学与技术专业考研方向有哪些
- 2025-06-01留学申请Top30有哪些高含金量竞赛?《2023TD竞赛白皮书》 涵盖理科/写作/商科/会议| 文末
- 2025-06-01工业工程专业考研方向分析
- 2025-06-01学美术去哪个国家留学比较好?必备指南
- 2025-06-01本科市场营销专业考研方向有哪些?可以考哪些专业?
- 2025-06-01英语专业考研的方向有哪些
- 2025-06-01英国哪些大学工科专业比较好?这10所顶尖英国大学不容错过
- 2025-06-01英语专业去英国读研有哪些选择
- 2025-06-01出国留学的好处与意义
-
 产品中心标题一
用于生产保险粉,磺胺二甲基嘧啶安乃近,己内酰胺等以及氯仿,苯丙砜和苯甲醛的净化。照相工业用作定影剂的配料。香料工业用于生产香草醛。用作酿造工业防腐剂,橡胶凝固剂和
产品中心标题一
用于生产保险粉,磺胺二甲基嘧啶安乃近,己内酰胺等以及氯仿,苯丙砜和苯甲醛的净化。照相工业用作定影剂的配料。香料工业用于生产香草醛。用作酿造工业防腐剂,橡胶凝固剂和 -
 产品中心标题二
用于生产保险粉,磺胺二甲基嘧啶安乃近,己内酰胺等以及氯仿,苯丙砜和苯甲醛的净化。照相工业用作定影剂的配料。香料工业用于生产香草醛。用作酿造工业防腐剂,橡胶凝固剂和
产品中心标题二
用于生产保险粉,磺胺二甲基嘧啶安乃近,己内酰胺等以及氯仿,苯丙砜和苯甲醛的净化。照相工业用作定影剂的配料。香料工业用于生产香草醛。用作酿造工业防腐剂,橡胶凝固剂和 -
 产品中心标题九
岗亭,英文名字为Watch House,字面理解就是岗哨工作的小房子。在车场管理中,岗亭常常也称之为收费亭,是停车场管理人员收取停车费的工作场所,除此以外还可用作小区保安门卫值
产品中心标题九
岗亭,英文名字为Watch House,字面理解就是岗哨工作的小房子。在车场管理中,岗亭常常也称之为收费亭,是停车场管理人员收取停车费的工作场所,除此以外还可用作小区保安门卫值 -
 产品中心标题八
岗亭,英文名字为Watch House,字面理解就是岗哨工作的小房子。在车场管理中,岗亭常常也称之为收费亭,是停车场管理人员收取停车费的工作场所,除此以外还可用作小区保安门卫值
产品中心标题八
岗亭,英文名字为Watch House,字面理解就是岗哨工作的小房子。在车场管理中,岗亭常常也称之为收费亭,是停车场管理人员收取停车费的工作场所,除此以外还可用作小区保安门卫值

